Let’s now apply conformal prediction to regression problems.
There is a naive approach where we calculate residuals directly on the training dataset.
However, if you train a machine learning model on a dataset , and then calculate your residuals using that exact same dataset, exchangeability no longer holds. The model overfits/optimizes on , minimizing the training residuals. This breaks exchangeability for because the test point wasn’t part of that optimization profile.
Split Conformal Prediction
Let be partitioned into two non-overlapping sets:
- Training Set : Used to optimize the model parameters to get .
- Calibration Set : Consisting of independent points.
Compute calibration residuals:
By sorting the calibration residuals () and choosing index , exchangeability guarantees:
The prediction set constructed with this out-of-sample threshold yields:
The upper bound of the coverage only holds if there are no ties (the no-ties condition):
Score Functions
We can use any score function as long as it treats data symmetrically. The metric is a conformity score function that quantifies how poorly a label fits an input given a frozen predictor .
A score is negatively-oriented if lower values imply a better, more accurate model prediction (e.g., standard absolute residuals ).
The valid prediction set:
Where is the -th smallest score observed in the calibration set .
A score is positively-oriented if higher values imply a better match (common in classification settings).
We invert the operator and threshold for the positive case:
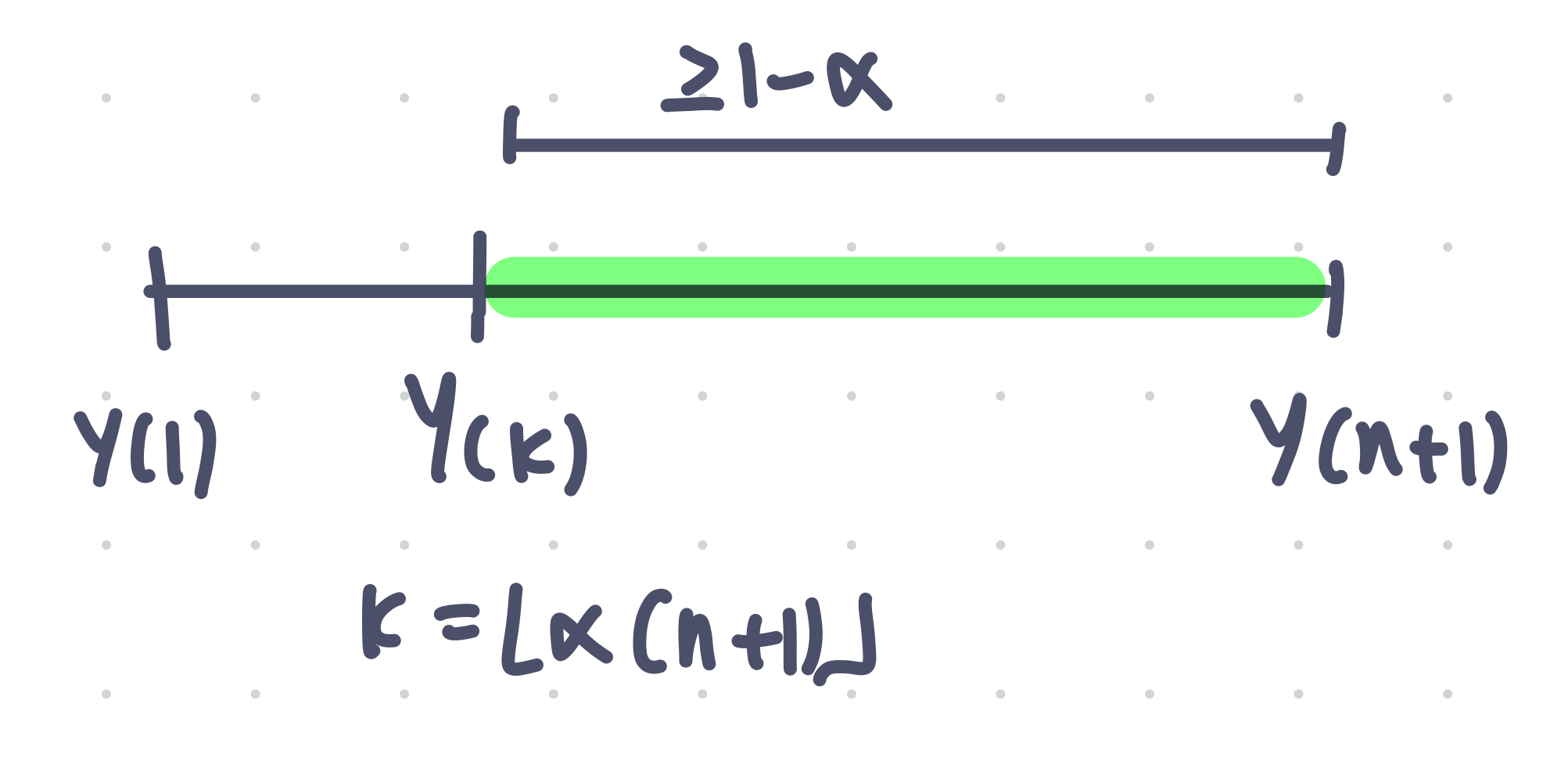
We define the valid prediction set with the following three equivalent statements.
- The Order Statistic Formulation
- The Empirical Quantile Formulation
- The Empirical Counting Formulation


Current Status: Formally proved the bijection between the ECDF, the empirical quantile function, and historical order statistics for split conformal prediction.
Next Objective: It turns out that split conformal prediction is not good as it has a constant width across all data points which means it may undercover and overcover at the same time.